
MySQL은 내부적으로 OS의 파일 I/O를 사용한다.
그럼 어느 정도는 직접 구현해볼 수 있지 않을까?
우선 MySQL의 아키텍처를 참고해보았다.

MySQL은 SQL 구문이 들어오면 Parser -> 전처리기 -> 옵티마이저 -> 엔진 실행기 -> 스토리지 엔진 순서로 동작한다.
설계
여기서 옵티마이저와 엔진 실행기는 제거하고 설계했다. 옵티마이저의 실행 계획 알고리즘 CBO를 구현할 역량이 없다고 생각했다. 또 내부적으로 실행 계획에 따라 풀스캔이나 인덱스로 탐색하는 것을 구현해야하는데, 마찬가지로 구현할 역량이 없다고 판단했다.
스토리지 엔진은 InnoDB를 참고했다.
그런 이유로 아키텍처는 아래와 같이 구성했다.
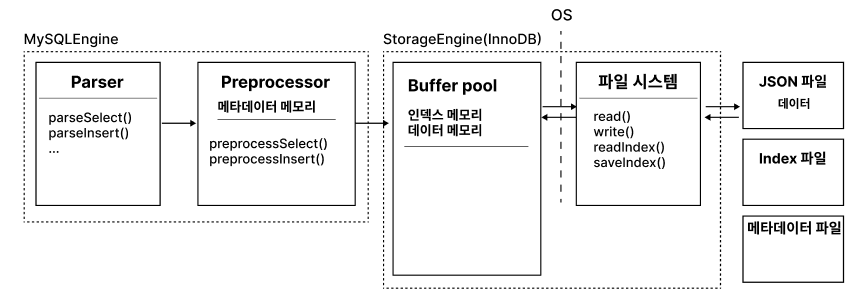
이번 구현에서 초점을 둔 것은, Disk I/O를 최대한 줄이는 것을 목표로 삼았다.
그런 이유로 두 가지를 중점을 두고 다루었는데, 캐시 메모리 관리와 파일을 Block 단위로 접근하는 것이다. 실제 MySQL도 위와 비슷하게 동작하기 때문에 많은 참고를 했다.
DB Server 초기화
app.ts
import DBServer from "./database/DBServer";
DBServer.start();
DBServer.ts
import BufferPool from "./BufferPool";
import Parser from "./Parser";
import Preprocessor from "./Preprocessor";
import FileSystem from "./FileSystem";
import SQLHandler from "./SQLHandler";
export default class DBServer{
public static parser: Parser;
public static preprocessor: Preprocessor;
public static bufferPool: BufferPool;
public static fileSystem: FileSystem;
public static sqlHandler: SQLHandler;
public static start(){
this.parser = new Parser();
this.preprocessor = new Preprocessor();
this.bufferPool = new BufferPool();
this.fileSystem = new FileSystem();
this.preprocessor.loadMetaData();
this.bufferPool.loadIndexData();
this.sqlHandler = new SQLHandler(this.parser, this.preprocessor, this.bufferPool);
}
}
app.ts가 실행될 때 DB 서버는 의존성과 preprocessor와 bufferPool의 메모리에 필요한 데이터를 로드한다.
preprocessor는 디스크 접근과는 거리가 먼 역할이다. 적합한 테이블이 존재하는지, column이 존재하는지를 체크한다. 실제 DB에서는 권한이 있는지도 체크한다.
그러기 위해서는 사실 디스크에 접근을 해야한다. 테이블과 컬럼이 디스크에 존재하기 때문이다. 그러나 매번 확인을 위해 디스크에 접근하면, 디스크 I/O가 생긴다.
이것을 막기 위해서 로드 시에 캐시 메모리를 디스크에서 불러오도록 했다.
Parser
Parser.ts
export default class Parser {
public parse(SQL: string){
const sql = SQL.toLowerCase();
const command = sql.split(" ")[0];
if(command ==='select'){
this.parserSelect(sql);
}
if(command ==='insert'){
this.parserInsert(sql);
}
}
public parserSelect(sql: string){
const selectRegex = /select (.+) from (\w+)(?: where (.+))?/i;
const match = sql.match(selectRegex);
if (!match) {
throw new Error('올바르지 않은 SELECT 구문');
}
const columns = match[1].split(',').map(col => col.trim());
const table = match[2];
const condition = match[3] ? match[3].trim() : null;
return {
command: 'select',
table,
columns,
condition
};
}
public parserInsert(sql: string){
const insertRegex = /insert into (\w+) \((.+)\) values \((.+)\)/i;
const match = sql.match(insertRegex);
if (!match) {
throw new Error('올바르지 않은 INSERT 구문');
}
const table = match[1];
const columns = match[2].split(',').map(col => col.trim());
const values = match[3].split(',').map(val => val.trim());
if (columns.length !== values.length) {
throw new Error('컬럼 수가 값의 수와 일치하지 않습니다.');
}
return {
command: 'insert',
table,
columns,
values
};
}
}
아주 간단한 DB 구현이 목표였기 때문에, Parser는 insert, select 만을 구현했고 select의 조건도 id를 조회하는 것만으로 제한해 구현했다.
정규 표현식을 통해 입력값을 검증한다.
Preprocessor
preprocessor는 DB에 적절한 테이블과 컬럼이 존재하는지를 체크한다. 위에서도 언급했지만, 그렇다면 여기서 파일 I/O가 이루어져야하는가에 대한 고민이 있었다.
실제 DB의 동작을 살펴보니 메타데이터를 미리 캐싱해둔다고 한다. DB 실행 시에, DB와 테이블 구조 정보를 메타데이터 파일에서 읽어와 메모리에 로드한다.
metadata.json
{
"tables": {
"user": {
"columns": ["id", "name", "email"],
"indexes": ["id"],
"auto_increment" : 1
},
"board": {
"columns": ["id", "title", "content", "userId"],
"indexes": ["id", "userId"],
"auto_increment" : 1
}
}
}
대략적인 metadata 형식은 이처럼 지정했다. auto_increment 는 삽입 시에 PK를 어떻게 처리를 할까 고민을 해보니, 이것도 마찬가지로 실제 디스크에 접근하기에는 리스크가 크기 때문에 메타 데이터에 저장해두었다.
Preprocessor.ts
import fs from 'fs';
export default class Preprocessor {
private metadataMemory: any;
public loadMetaData(){
const filePath = `${process.cwd()}/src/database/files/metadata.json`;
const rawData = fs.readFileSync(filePath, 'utf-8');
this.metadataMemory = JSON.parse(rawData);
}
public preprocessInsert(parsedQuery: any){
const { table, columns, values } = parsedQuery;
if(!this.isTableExist(table)) throw new Error(`해당 테이블이 존재하지 않습니다. table: ${table}`);
if(!this.isColumnExist(table, columns)) throw new Error(`컬럼이 테이블에 존재하지 않습니다. column: ${columns}, table: ${table}`);
}
public preprocessSelect(parsedQuery: any){
const { table, columns, condition } = parsedQuery;
if(!this.isTableExist(table)) throw new Error(`해당 테이블이 존재하지 않습니다. table: ${table}`);
if(!this.isColumnExist(table, columns)) throw new Error(`컬럼이 테이블에 존재하지 않습니다. column: ${columns}, table: ${table}`);
if(!this.validCondition(table, condition)) throw new Error(`적합하지 않은 조건입니다. condition: ${condition}, table: ${table}`);
}
public isTableExist(tableName: string){
return !!(this.metadataMemory.tables[tableName]);
}
public isColumnExist(table: string, columns: string[]){
columns.forEach((column: string) => {
if (column!="*"&&!this.metadataMemory.tables[table].columns[column]) {
return false;
}
});
return true;
}
public validCondition(table: string, condition: string){
const [column, value] = condition.split("="); //id=1
if (!this.metadataMemory.tables[table].columns[column]) {
return false;
}
return true;
}
}
아주 간단한 preprocessor 이다. 테이블과 컬럼, 조건이 일치하는지 정도로만 체크했다. 위에서 언급했던 것처럼 캐시된 메모리를 이용한다.
만약 값이 변경되거나 테이블이 변경되면 캐시를 수정해야하는 로직이 필요하다.
BufferPool
인덱스 파일을 따로 두어야하나 싶은 고민을 했다. 왜냐하면 인덱스 파일을 읽어와 다시 해당하는 데이터 파일로 접근하면 두 번의 I/O가 생기고, 그럴바에는 데이터 파일을 읽어버리는게 더 빠르지 않나 라는 고민을 했다.
하지만 인덱스 파일은 휘발되면 안되는 데이터이기 때문에 파일로 두어야만 했다.
그래서 실제 mysql의 동작을 확인해보니, 인덱스 파일도 innoDB의 버퍼 풀에서 캐시로 관리한다는 것을 알았다. 해당 부분을 고려해 버퍼풀 클래스에 메모리를 만들어두었다.
BufferPool.ts
import FileSystem from './FileSystem';
export default class BufferPool {
private indexMemory = new Map();
private dataMemory = new Map();
private fileSystem: FileSystem;
constructor() {
this.fileSystem = new FileSystem();
}
public loadIndexData(){
const rawData = this.fileSystem.readIndexData();
this.indexMemory = new Map(Object.entries(JSON.parse(rawData)).map(([key, value]) => [Number(key), value]));
}
//id로 조회하는 경우만으로 한정
public findInBufferPool(table:string, columns:string[], condition:string){
if(condition){
const [key, index] = condition.split("=");
if(key==='id'){
const data = this.dataMemory.get(`${table}-${index}`);
if(data){
if(columns[0]==="*") return data;
else{
const filteredData:Record<string, any> = {};
columns.forEach(col => {
filteredData[col] = data[col];
});
return filteredData;
}
}
}
}
return null;
}
public loadData(table: string, id: number|null=null){
if(!id){
this.loadFullDataFromFile(table);
}else{
this.loadDataByIdFromFileAndCache(table, id);
}
}
public loadDataByIdFromFileAndCache(table: string, id: number) {
const blockInfo = this.indexMemory.get(`${table}-${id}`);
if (!blockInfo) {
throw new Error(`ID에 해당하는 블록을 찾을 수 없습니다: ${id}`);
}
const rawData = this.fileSystem.readBlock(table, blockInfo);
const data = JSON.parse(rawData);
this.dataMemory.set(`${table}-${id}`, data);
return data;
}
public loadFullDataFromFile(table: string) {
const rawData = this.fileSystem.readFullTable(table);
const data = JSON.parse(rawData);
return data;
}
public insertDataToFileAndBuffer(table: string, id: number, data: any) {
const {blockStart, rawData} = this.fileSystem.writeBlock(table, data);
this.indexMemory.set(`${table}-${id}`, { offset: blockStart, length: rawData.length });
this.dataMemory.set(`${table}-${id}`, data);
this.fileSystem.saveIndexData(this.indexMemory);
}
}
버퍼풀은 innoDB의 버퍼풀을 참고했다.
만약 데이터를 메모리에서 찾으면, 메모리에서 반환을 하고 만약 메모리에 없다면 디스크에 접근한다.
저장 방식에 대한 고민
목표는 파일 I/O를 최대한 줄이는 것이다. (물론 JSON 파일을 통채로 읽어와 캐시로 적재할 수는 있지만, 그렇게 하면 실제 DB의 동작과 거리가 있다고 생각했다.)
실제 InnoDB에서도 Page라는 블록 단위로 데이터를 저장하고 읽어온다.
우선 JSON 으로 데이터를 저장을 한다.
그럼 만약 10만개의 데이터를 하나의 파일에 전부 몰아넣어야할까? 분리해서 저장한다면 어느정도로 분리를 해야하고, 파일명을 어떻게 지어야할까?
(1) DB에서처럼 페이지 단위로 나누어서 저장 파일명을 페이지 번호로 두고, 인덱스 파일에 key, value 형태로 두어 해당하는 파일로 접근한다.
이렇게 구현하면 파일 크기도 줄고, 데이터를 가져오기가 편할 것이란 생각이 든다. 다만, 데이터가 수정 삭제될 때에 로직이 훨씬 복잡해진다.
(2) 한 파일에 다 저장하고 fileDescriptor.read() 메서드를 이용해 특정 부분만 읽어오기
fileDescriptor.read는 파일의 특정 부분만 읽을 수 있는 기능을 제공한다. 파일을 메모리에 다 올리지 않고, 지정한 바이트 범위만 읽어온다. 여기서도 인덱스 파일에는 offset을 저장하고 fileDescriptor에 해당 범위를 가져오게끔한다.
간단 DB를 구현하며 흐름을 파악하는 것이 목표이기 때문에, 2번 방법을 사용하게 되었다.
FileSystem.ts
import fs from 'fs';
export default class FileSystem {
private readonly BLOCK_SIZE = 1024; //1KB
public readFullTable(table: string){
const filePath = `${process.cwd()}/src/database/files/table/${table}.data`;
const rawData = fs.readFileSync(filePath, 'utf-8');
return rawData;
}
public readBlock(table:string, blockInfo: any){
const { offset, length } = blockInfo;
const filePath = `${process.cwd()}/src/database/files/table/${table}.data`;
const fd = fs.openSync(filePath, 'r');
const buffer = Buffer.alloc(length);
fs.readSync(fd, buffer, 0, length, offset);
fs.closeSync(fd);
const rawData = buffer.toString('utf-8').trim();
return rawData;
}
public writeBlock(table: string, data: any){
const filePath = `${process.cwd()}/src/database/files/table/${table}.data`;
const rawData = JSON.stringify(data, null, 2);
if (rawData.length > this.BLOCK_SIZE) {
throw new Error(`데이터가 블록 크기(${this.BLOCK_SIZE}바이트)를 초과했습니다.`);
}
const fd = fs.openSync(filePath, 'a');
const blockStart = fs.fstatSync(fd).size;
const buffer = Buffer.alloc(this.BLOCK_SIZE, ' ');
buffer.write(rawData);
fs.writeSync(fd, buffer);
fs.closeSync(fd);
return {blockStart, rawData};
}
public saveIndexData(indexMemory:any) {
const filePath = `${process.cwd()}/src/database/files/index.json`;
fs.writeFileSync(filePath, JSON.stringify(Object.fromEntries(indexMemory), null, 2), 'utf-8');
}
public readIndexData() {
const filePath = `${process.cwd()}/src/database/files/index.json`;
const rawData = fs.readFileSync(filePath, 'utf-8');
return rawData;
}
public readMetaData() {
const filePath = `${process.cwd()}/src/database/files/metadata.json`;
const rawData = fs.readFileSync(filePath, 'utf-8');
return rawData;
}
}
그래서 파일 시스템에 접근하는 것은 이처럼 구현했다. 저장과 조회를 블럭 단위로 이루어지도록 구현하였다.
SQL Handler
SQL Handler.ts
import BufferPool from "./BufferPool";
import Parser from "./Parser";
import Preprocessor from "./Preprocessor";
export default class SQLHandler {
private parser: Parser;
private preprocessor: Preprocessor;
private bufferPool: BufferPool;
constructor(parser: Parser, preprocessor: Preprocessor, bufferPool: BufferPool) {
this.parser=parser;
this.preprocessor=preprocessor;
this.bufferPool=bufferPool;
}
public query(sql: string) {
const parsedQuery = this.parser.parse(sql);
this.queryProcess(parsedQuery);
}
public queryProcess(parsedQuery: any){
if (parsedQuery.command === 'select') {
const { table, columns, condition } = parsedQuery;
this.preprocessor.preprocessSelect(parsedQuery);
const cachedData = this.bufferPool.findInBufferPool(table, columns, condition);
if(cachedData){
return cachedData;
} else {
const data = this.bufferPool.loadData(table, condition?condition.split('=')[0]:null);
return data;
}
} else if (parsedQuery.command === 'insert') {
const { table, columns, values } = parsedQuery;
this.preprocessor.preprocessInsert(parsedQuery);
}
//TODO: 다른 명령어 추가하기
else {
throw new Error(`SQL command 오류: ${parsedQuery.command}`);
}
}
}
쿼리를 실행하는 핸들러는 이처럼 구현했다.
this.sqlHandler.query(
'select A from table'
)
와 같이 사용할 수 있게 구현했다.
'Backend > MySQL' 카테고리의 다른 글
| 자주 바뀌는 데이터, 정적 테이블에 넣어도 괜찮을까 (2) | 2025.06.05 |
|---|---|
| [MySQL] DROP 명령어는 어떻게 테이블을 통채로 날릴까? (0) | 2024.11.12 |
| 100만개의 데이터, 경우에 따른 실행 계획 확인해보기 (0) | 2024.10.16 |
| [MySQL] DB의 인덱스로 B+트리를 사용하는 이유 (0) | 2024.09.28 |
| [MySQL] MySQL 아키텍처를 간단히 살펴보기 (0) | 2024.08.10 |