[운영체제] 메모리 구조 : 스택과 힙 다시 살펴보기
프로세스 메모리 구조
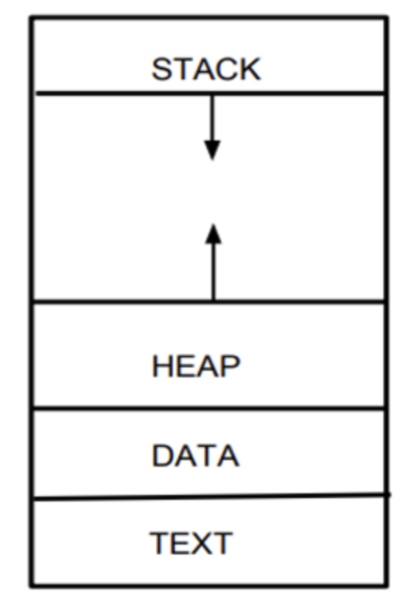
프로세스의 메모리 영역은 여러 부분으로 나뉜다. 우선 간단하게 Stack, Heap, TEXT 영역의 개념을 살펴보자!
Stack
스택은 함수 호출과 관련된 정보를 저장하는 메모리 공간이다. 함수를 호출할 때마다 함수의 매개변수, 반환 주소, 지역 변수가 스택에 저장된다.
함수 호출시 새로운 stack 프레임이 생성되어 스택에 쌓이고, 함수 종료시 해당 스택 프레임이 제거 된다.
스택 프레임이란?
스택 프레임은 쉽게 말해 함수의 호출 정보 모음이다. 함수 호출시 스택 영역에 차례대로 저장되는 것들을 말한다. 스택 프레임이라는 개념 덕분에 함수가 종료되면 이전 상태로 되돌아갈 수 있다.
HEAP
힙은 동적 메모리 할당이 수행되는 공간이다. 이것을 풀어서 쉽게 생각해보면, 개발자가 실행 중에 말 그대로 동적으로 할당할 수 있는 공간이다. 동적으로 관리되는 자료구조를 사용할 때 주로 활용된다.
malloc, calloc, realloc , free함수를 통해 힙을 관리한다.
스택과 힙의 차이는 무엇일까
- 메모리 관리
우선 메모리를 관리하는 부분에서 차이가 난다.
스택은 자동으로 메모리가 할당되고 할당 해제되지만, 힙은 개발자가 수동으로 메모리를 할당하고 해제한다.
- 메모리 문제
그런 이유로 메모리와 관련해 생기는 문제도 조금 차이가 있다. 스택은 메모리가 부족할 가능성이 높다는 것이 문제이고, 힙은 주요 문제가 메모리 단편화가 있다.
메모리 fragmentation
쉽게 말하면, 메모리가 사용할 공간이 있는데도 할당이 불가능한 상태이다.
내부 단편화와 외부 단편화가 있는데, 내부 단편화는 메모리를 할당할 때 프로세스가 필요한 양보다 더 큰 메모리가 할당되는 것이고, 외부 단편화는 중간의 사용하지 않는 메모리가 많이 존재해서 총 메모리 공간은 충분하지만 실제로 할당할 수 없는 상황을 말한다.
반면, 스택은 말그대로 차곡차곡 쌓는 방식이기 때문에, 낭비되는 공간이 없다.(하지만 용량이 작음)
- 유연성
스택은 유연하지 않아 할당된 메모리 크기를 변경할 수 없다는 단점이 있다.
CODE
코드 영역은 프로그램의 실행 가능한 명령어들이 저장되는 공간이다. CPU는 여기서 명령어를 읽어와 실행한다.
이 영역은 읽기 전용으로 설정되어 있어, 프로그램이 실행 중에 명령어를 수정하지 못하도록 되어있다.
조금 더 파헤쳐 보기!
이제 각 개념들을 알아보았으니, 그림을 한번 자세히 들여다보자
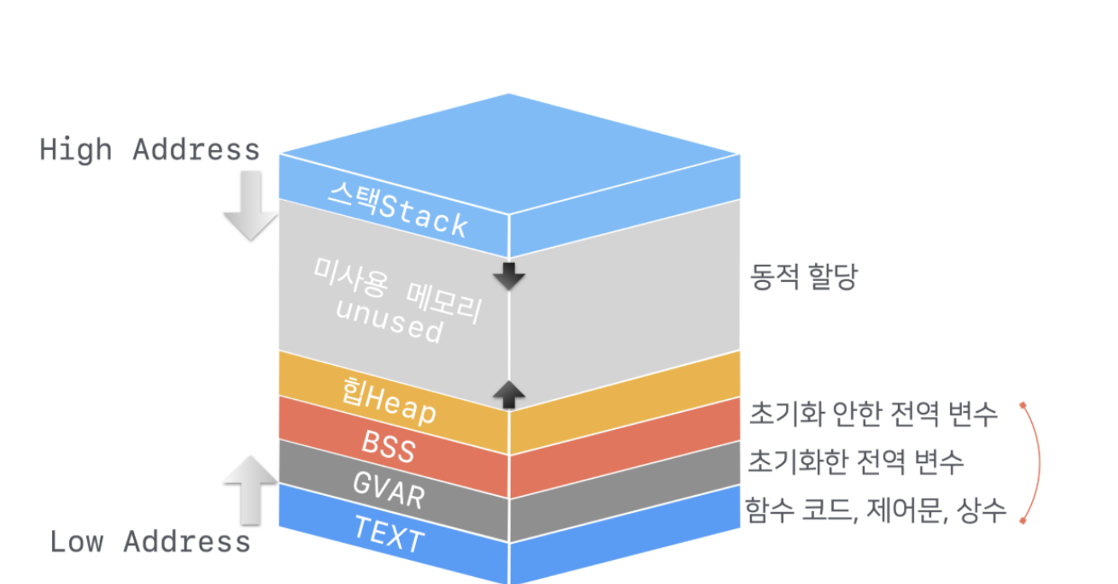
위 그림을 보고 궁금한 것이 두 가지가 생겼다.
첫째로 Stack은 High Address, 그리고 TEXT는 Low Address에 위치하는데 여기서 High와 Low는 무엇인가?
그리고 Stack의 저장 방향은 아래로 향하고, Heap은 위로 향하는 이유가 무엇일까?
High Address와 Low Address
High address는 사용자 공간 주소, low address는 커널 메모리 주소이다.

다시 그림으로 표현해보면, 물리적 메모리의 구조는 이렇게 크게 두 가지로 구분할 수 있다. 낮은 주소 쪽에는 운영 체제 커널이 항상 상주한다. 그리고 높은 곳은 사용자 프로그램이 있다.
왜 낮은 주소에 운영체제 커널이 상주하게 되었을까?
이것에 대한 이유는 사실 당연한데, CPU가 낮은 주소부터 명령어를 실행하기 때문에, 부팅에 필요한 OS 데이터가 가장 낮은 곳에 위치하는 것이다. (메모리가 텅 빈 컴퓨터가 오면 당장 필요한 OS를 먼저 넣는 느낌이랄까)
그리고 메모리가 낮을수록 빠르게 접근할 수 있다는 것도 이유이다.
그렇다면 이렇게 크게 두 가지를 나누는 이유가 무엇일까??
바로 사용자 프로그램이 커널 메모리 영역에 접근하는 것을 방지하기 위함이다! 사용자 프로그램 관련 메모리가 커널에 넘어가 값이 겹치게 되면 큰 문제가 생기게 된다.
이런 이유는 위에서 언급한, Stack과 Heap의 저장 방향과도 연결된다.
Stack은 아래로, Heap은 위로 향하는 이유?
Heap은 OS 상주 영역 근처에 위치한다. Heap이 위로 쌓이게 되면 OS 상주 영역과 마주칠 일이 없어 안정성이 보장된다.
Stack와 힙은 서로를 바라보고 값을 저장한다. 이런 이유는 주소 공간을 효율적으로 사용하기 위함인데, 두 영역이 충돌하기 전까지 메모리 전체를 사용할 수 있기 때문이다.

그래서 서로의 영역을 침범하는 경우가 생길 수도 있다. 힙이 넘치면 힙 오버플로우, 스택이 넘치면 스택오버플로우라고 한다.
스택은 빠르고 힙은 느리다
스택은 빠르고 힙은 느리다라는 말을 들어본 적이 있다. 왜 그런 것일까.
메모리의 할당과 해제부분에서 한번 생각해볼 수 있다.
스택은 마지막에 저장된 데이터에 가장 먼저 접근할 수 있다는 점, 그리고 스택 포인터로 그 부분의 메모리를 할당하고 해제하기만 하면 된다.
하지만 힙은 메모리 할당과 해제 시에 복잡한 관리 작업이 필요하다.
쉽게 생각해보자. 힙은 동적 메모리 할당을 한다.
이 얘기를 풀어서 써보면, 프로그램마다 다양한 크기의 메모리 블록 요청이 들어올 수 있다는 것이고, 또 할당 요청이 빈번하게 발생하는데다가 각 요청마다 요구되는 크기가 다르기 때문에 관리가 복잡하다.
또 위에서 언급한 것처럼 힙을 해제하면 메모리 단편화 문제도 생기게 되고, 힙에 할당 요청이 들어오면 알맞은 블럭의 위치를 찾아야한다.
이렇게 여러가지를 고려해서 메모리를 관리하기 때문에 당연히 스택보다 느릴 수 밖에 없는 것이다.
그렇다면 모든 것을 스택으로 구현하면 빠르고 좋은거 아닌가..?
이런 생각도 해보았는데 모든 메모리를 스택으로 구현하게 되면 구조적으로 제한이 생기게 된다.
스택 방식의 큰 특징은 항상 최상단 요소에만 접근할 수 있다는 것이다. 그래서 복잡한 데이터 구조를 구현하는 것에 매우 부적합하다.
하지만 힙은 포인터를 통해 임의의 위치에 접근이 가능하기 때문에, 복잡한 데이터 구조도 구현할 수 있다.
애초에 이런 제한을 극복하기 위해 힙을 쓰는 것이기 때문에, 이 정도로 각 영역의 차이를 알아두면 좋을 것 같다.
Heap 메모리 파편화 문제를 해결하는 방법
힙에서는 언급했듯 메모리 파편화 문제가 생긴다. 이것은 어떻게 해결할 수 있을까?
힙의 할당 블록을 어떻게 찾을지를 정할 알고리즘과 메모리를 압축하는 방법이 있다. (가비지 컬렉션도 물론 해결에 도움된다!)
알고리즘은 굉장히 단순해서 간단히만 언급하자면, 그냥 가장 앞에 보이는 블록을 찾는 First Fit, 그리고 가장 크기와 맞는 블록을 할당하는 BestFit, 할당 이후 가장 앞의 블록을 찾는 Next Fit이 있다.

메모리 압축은 사용 중인 메모리를 한쪽으로 몰아서 빈 블록을 크게 만드는 것이다. 이렇게 하면 메모리 사이의 틈이 없어져 단편화를 줄일 수 있다.
물론 메모리를 옮기는데 오버헤드가 크다는 점은 유의해야한다!